从零开始使用Rust写一个基于RISC-V架构的类Unix内核.
前置知识:
- Rust基础语法和一些进阶语法(Trait、函数式编程,Unsafe)
- Git
- 简单汇编
参考文档:
构建应用程序#
执行此命令创建一个名为os的项目。
1
2
3
| fn main() {
println!("Hello, world!");
}
|
创建项目后os/src/main.rs中已经有了“Hello, world!”的代码。
打开os文件夹后,执行此命令后可以看到控制台输出Hello, world!。
但是,我们享受到的编程和执行程序如此方便背后有着从硬件到软件的多种机制的支持。尤其是对于应用程序的运行,需要有一个强大的执行环境来帮助。
应用程序执行环境#
现代通用操作系统上的应用程序运行需要下面多层次的执行环境栈的支持:
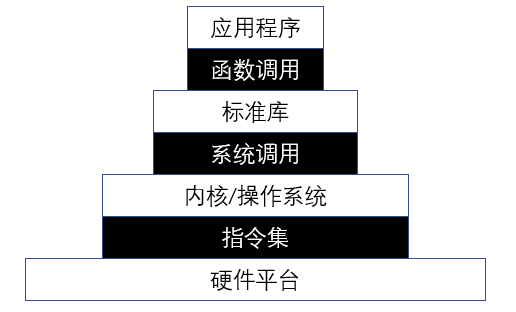
我们的应用位于最上层,可以通过调用不同编程语言提供的标准库或者其他第三方库对外提供的功能强大的函数接口,使得仅需少量的代码就能完成复杂的功能。实际上这些库属于应用程序的执行环境(Execution Environment),在我们通常不会注意到的地方,它们还会在执行应用之前完成一些初始化工作,并在应用程序执行的时候对它进行监控。
从内核/操作系统的角度来看,它上面的一切都属于用户态,而它自身属于内核态。无论用户态应用如何编写,某些功能总要直接或者间接的通过内核/操作系统提供的系统调用(System Call)来实现。因此系统调用充当了用户和内核之间的边界。
内核作为用户态的执行环境,它不仅要提供系统调用接口,还需要对用户态应用的执行进行监控的管理。
平台与目标三元组#
现代编译器工具集以C编译器为例,主要工作流程如下:
1
2
3
4
| 1. 预处理: 源代码(source code) -> 预处理器(preprocessor) -> 宏展开的源代码
2. 编译: 宏展开的源代码 -> 编译器(compiler) -> 汇编程序
3. 汇编: 汇编程序 -> 汇编器(assembler) -> 目标代码(object code)
4. 链接: 目标代码 -> 链接器(linker) -> 可执行文件(executables)
|
编译应用程序时,编译器将其源代码通过编译、链接得到的可执行文件时需要知道程序要在哪个平台运行。这些平台主要指CPU类型、操作系统类型和标准运行时库的组合。
我们通过``目标三元组(Target triple)`来描述一个目标平台。它一般包括CPU架构、CPU厂商、操作系统和运行时库。
我们可以通过rustc来输出rust的默认配置信息:
1
2
3
4
5
6
7
8
| $ rustc --version --verbose
rustc 1.63.0 (4b91a6ea7 2022-08-08)
binary: rustc
commit-hash: 4b91a6ea7258a947e59c6522cd5898e7c0a6a88f
commit-date: 2022-08-08
host: aarch64-apple-darwin
release: 1.63.0
LLVM version: 14.0.5
|
执行结果中,host表明默认目标平台是aarch64-apple-darwin,CPU架构是aarch64,供应商是apple,操作系统是darwin。
我们想要在另一个硬件平台上运行Hello, world!,这与之前的默认平台不同,CPU架构需要从aarch64换到risc-v。
通过rustc来输出Rust编译器支持那些基于risc-v的平台:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| $ rustc --print target-list | grep riscv
riscv32gc-unknown-linux-gnu
riscv32gc-unknown-linux-musl
riscv32i-unknown-none-elf
riscv32im-unknown-none-elf
riscv32imac-unknown-none-elf
riscv32imac-unknown-xous-elf
riscv32imc-esp-espidf
riscv32imc-unknown-none-elf
riscv64gc-unknown-freebsd
riscv64gc-unknown-linux-gnu
riscv64gc-unknown-linux-musl
riscv64gc-unknown-none-elf
riscv64imac-unknown-none-elf
|
修改目标平台#
我们希望将程序一直到RICV目标平台riscv64gc-unknown-none-elf上运行。
- PS:
riscv64gc-unknown-none-elf 的CPU架构是riscv64gc,厂商是unknown,操作系统是none, elf表示没有标准的运行时库。没有任何系统调用的封装支持,但可以生成ELF格式的执行程序。我们不选择有linux-gnu支持的riscv64gc-unknown-linux-gnu,是因为我们的目标是开发操作系统内核,而非在linux系统上运行的应用程序。
使用cargo编译或编译运行时,可以使用 --target <target triple>来支持不同平台。
1
| cargo run --target riscv64gc-unknown-none-elf
|
执行此命令后报错,是由于目标平台上没有Rust标准库std,也不存在任何受OS支持的系统调用,这样的平台我们称为裸机平台(bare-metal)。
既然不支持rust的std标准库,那为什么要使用rust呢?
除了std之外,rust还有一个不需要任何操作系统支持的核心库core,它包含了rust相当一部分的核心机制。
移除标准库依赖#
接下来将移植上述的Hello, world!程序到RV64GC平台,所以我们要移除程序对Rust std标准库的依赖 ,
因为Rust std标准库需要操作系统内核的支持。我们需要添加能够支持应用的裸机级别的库操作系统(LibOS)。
由于后续需要rustc编译器缺省生成RISC-V 64 的目标代码,首先需要给rustc添加一个target: riscv64gc-unknown-none-elf
1
| $ rustup target add riscv64gc-unknown-none-elf
|
然后在os目录下新建.cargo目录,再次目录下创建config文件
1
2
3
| # os/.cargo/config
[build]
target = "riscv64gc-unknown-none-elf"
|
做此调整之后,Cargo默认会使用riscv64gc作为目标平台。
之后执行cargo build输出如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| $ cargo build
Compiling os v0.1.0 (/Users/ther/WorkSpace/rCore/os)
error[E0463]: can't find crate for `std`
|
= note: the `riscv64gc-unknown-none-elf` target may not support the standard library
= note: `std` is required by `os` because it does not declare `#![no_std]`
error: cannot find macro `println` in this scope
--> src/main.rs:2:5
|
2 | println!("Hello, world!");
| ^^^^^^^
error: `#[panic_handler]` function required, but not found
For more information about this error, try `rustc --explain E0463`.
error: could not compile `os` due to 3 previous errors
|
我们来解释报错信息:
- 第一个error表示没有找到标准库std。具体原因报错信息也做了解释,
riscv64gc-unknown-none-elf作为目标平台,并不支持标准库std。可以使用#![no_std]来告诉Rust编译器不使用std标准库而是使用``core`。 - 第二个error表示没有找到
println!宏。这是由于之前println!宏由std标准库提供,此时并不能支持std标准库,而我们也没能自己实现。 - 第三个error是由于没能找到
panic!宏的具体实现,这个原因有点类似于第二个error的原因。使用Rust编写程序时,我们常常会遇到一些无法恢复的致命错误,导致程序无法继续运行,这时会手动或自动调用panic!宏来打印错误的位置。所以Rust编译器在编译程序时,从安全性考虑,需要有panic!宏的具体实现。在std标准库中提供了panic!的具体实现,但是在更底层的核心库core中只有一个panic!宏的空壳,所以我们需要先自行实现一个简陋的panic处理函数。报错信息中也给出了提示,使用#[panic_handler]。
1
2
3
4
5
| // os/src/main.rs
#![no_std]
mod lang_items;
fn main() {}
|
1
2
3
4
5
6
7
| // os/src/lang_items.rs
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {
loop {}
}
|
执行cargo build后依旧会报错:
1
2
3
4
5
| $ cargo build
Compiling os v0.1.0 (/Users/ther/WorkSpace/rCore/os)
error: requires `start` lang_item
error: could not compile `rCore` due to previous error
|
编译器提示我们缺少了一个名为start的语义项。之前提到语言标准哭和三方库作为应用程序的执行环境,需要负责在执行应用程序之前进行一些初始化工作,然后才跳转到应用程序的入口点(跳转到我们编写的main函数)开始执行。实际上start语义项代表了std标准库在执行应用程序之前需要进行的一些初始化工作。由于我们禁用了标准库,编译器也就找不到这项功能的实现了。
最简单的解决方案就是直接不让编译器使用这项功能。
1
2
3
4
5
| // os/src/main.rs
#![no_std]
#![no_main]
mod lang_items;
//在开头加入设置#![no_main]告诉编译器我们没有一般意义上的main函数,并删除原来的main函数。
|
1
2
3
| $ cargo build
Compiling os v0.1.0 (/Users/ther/WorkSpace/rCore/os)
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
|
至此,我们成功的移除了标准库依赖,通过了编译器检查并生成执行码。但是原有的功能却被弱化甚至删除,接下来我们会以自己的方式来重塑这些基本功能。
分析被移除标准库的程序#
对于上面这个被移除标准库的应用程序,通过了编译器的检查和编译,形成了二进制代码。但这个二进制代码是怎样的,它能否被正常执行呢?为了分析这些程序,首先需要安装 cargo-binutils 工具集:
1
2
| $ cargo install cargo-binutils
$ rustup component add llvm-tools-preview
|
我们可以通过各种工具来分析目前的程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| # 文件格式
$ file target/riscv64gc-unknown-none-elf/debug/os
target/riscv64gc-unknown-none-elf/debug/os: ELF 64-bit LSB executable, UCB RISC-V, RVC, double-float ABI, version 1 (SYSV), statically linked, with debug_info, not stripped
# 对二进制程序os的分析可以看出它好像是一个合法的RISC-V可执行程序
# 文件头信息
$ rust-readobj -h target/riscv64gc-unknown-none-elf/debug/os
File: target/riscv64gc-unknown-none-elf/debug/os
Format: elf64-littleriscv
Arch: riscv64
AddressSize: 64bit
LoadName: <Not found>
ElfHeader {
Ident {
Magic: (7F 45 4C 46)
Class: 64-bit (0x2)
DataEncoding: LittleEndian (0x1)
FileVersion: 1
OS/ABI: SystemV (0x0)
ABIVersion: 0
Unused: (00 00 00 00 00 00 00)
}
Type: Executable (0x2)
Machine: EM_RISCV (0xF3)
Version: 1
Entry: 0x0
ProgramHeaderOffset: 0x40
SectionHeaderOffset: 0x1B40
Flags [ (0x5)
EF_RISCV_FLOAT_ABI_DOUBLE (0x4)
EF_RISCV_RVC (0x1)
]
HeaderSize: 64
ProgramHeaderEntrySize: 56
ProgramHeaderCount: 3
SectionHeaderEntrySize: 64
SectionHeaderCount: 14
StringTableSectionIndex: 12
}
# 通过rust-readobj工具进一步分析,发现入口地址Entry是0x0
# 反汇编导出汇编程序
$ rust-objdump -S target/riscv64gc-unknown-none-elf/debug/os
target/riscv64gc-unknown-none-elf/debug/os: file format elf64-littleriscv
# 经过反汇编,并没有生成汇编代码,所以基本可以断定,这个二进制程序虽然合法,但它是一个空程序。
|
QEMU模拟器#
我们编写的内核主要在Qemu模拟器上运行来检验其正确性。
1
2
3
4
5
6
| # 此命令用于启动Qemu并运行我们的内核
$ qemu-system-riscv64 \ # 模拟64位RISC-V架构的计算机
-machine virt \ # 将模拟的64位RISC-V计算机设置为名为virt的虚拟计算机
-nographic \ # 表示不需要提供图形界面
-bios ../bootloader/rustsbi.bin \ # Qemu开机时用来初始化的引导加载程序bootloader
-device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000 # loader属性可以在Qemu开机前将宿主机的文件载入到指定物理内存地址。
|
virt平台,物理内存的起始物理地址为0x80000000,物理内存的默认大小为128MiB,物理内存可以通过-m进行调整。
计算机加电之后的启动流程可以分成若干个阶段,每个阶段由一层软件负责,承担相应的初始化工作,并在此之后跳转到下一层软件的入口地址,也就是将计算机的控制权移交给下一层软件。Qemu模拟的启动流程分为三个阶段:
- 由固化在Qemu中的一小段汇编程序负责
- 由bootloader负责
- 由内核镜像负责。
在使用上述命令启动Qemu后,bootloader将被加载到物理地址以0x80000000开头的区域,同时内核镜像将被加载到物理地址以0x80200000开头的区域。
程序内存布局与编译流程#
程序内存布局#
将源代码编译为可执行文件后,这些看似杂乱无章的字节可以被分成代码和数据两部分:
- 代码部分由一条条可以被CPU解码并执行的指令组成
- 数据部分只是被CPU视作可读写的内存空间
实际上,我们还可以根据具体功能将这两个部分划分为更小的单位:段(Section)。不同的段被编译器放在内存不同的位置上,这就构成了程序的内存布局。一种典型的程序相对内存布局如下:
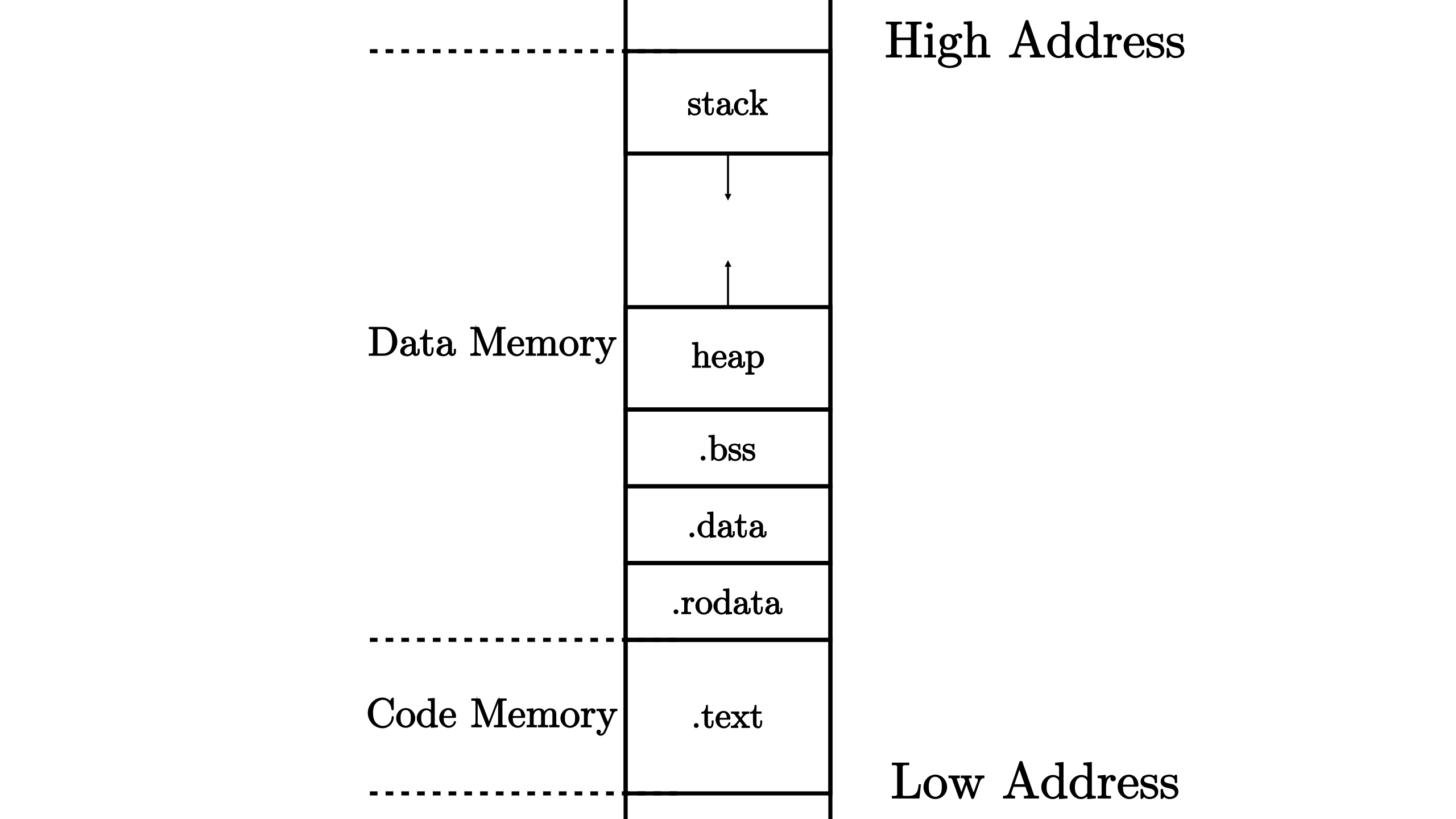
.text:代码段,存放程序所有的汇编代码.rodata:已初始化数据段,只读全局数据,通常是一些常熟或者是常量字符串.data:已初始化数据段,可修改的全局数据.bss:未初始化数据段,保存程序中为初始化的全局变量,通常由程序的加载者代为进行数据零初始化heap:堆,用于存放程序运行时动态分配的数据,向高地址增长stack:栈,不仅用于函数调用上下文的保存与恢复,每个函数作用域的局部变量也被编译器放在它的栈帧内,向低地址增长
编译流程#
从源代码到可执行文件的编译流程可以被细化成多个阶段:
汇编器输出的每个目标文件都有一个独立的内存布局,它描述了目标文件内各段所在的位置。而链接器所做的事情就是将所有输入的目标文件整合成一个整体的内存布局:
- 首先将不同目标文件的段在目标内存布局中重新排布,内存布局存在冲突则合并消除冲突
- 其次将符号替换为具体地址
内核的第一条指令#
1
2
3
4
5
| # os/src/entry.asm
.section .text.entry # 表示将后面的内容放到名为.text.entry 的段中
.global _start # 告知编译器,这是一个全局符号,可以被其他目标文件使用
_start:
li x1, 100 # 向寄存器x1中加载一个立即数100
|
在main.rs中嵌入这段汇编代码
1
2
3
4
5
6
7
| // os/src/main.rs
#![no_std]
#![no_main]
mod lang_items;
use core::arch::global_asm;
global_asm!(include_str!("entry.asm"));
|
调整内核的内存布局#
为了实现与Qemu的正确对接,我们可以通过链接脚本调整链接器的行为。
1
2
3
4
5
6
7
8
9
| # os/.cargo/config
[build]
target = "riscv64gc-unknown-none-elf"
[taaarget.riscv64gc-unknown-none-elf]
rustflags = [
"-Clink-arg=-Tsrc/linker.ld", "-Cforce-frame-pointers=yes",
]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| # os/src/linker.ld
OUTPUT_ARCH(riscv) # 设置目标平台
ENTRY(_start) # 设置整个程序的入口点,_start为entry.asm中定义的全局符号
BASE_ADDRESS = 0x80200000; # 定义常量
SECTIONS
{
. = BASE_ADDRESS;
skernel = .;
stext = .;
.text : {
*(.text.entry) # *
*(.text .text.*)
}
. = ALIGN(4K);
etext = .;
srodata = .;
.rodata : {
*(.rodata .rodata.*)
*(.srodata .srodata.*)
}
. = ALIGN(4K);
erodata = .;
sdata = .;
.data : {
*(.data .data.*)
*(.sdata .sdata.*)
}
. = ALIGN(4K);
edata = .;
.bss : {
*(.bss.stack)
sbss = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
}
. = ALIGN(4K);
ebss = .;
ekernel = .;
/DISCARD/ : {
*(.eh_frame)
}
}
|
之后执行命令:
1
2
3
| $ cargo build --release
Compiling os v0.1.0 (/Users/ther/WorkSpace/rCore/os)
Finished release [optimized] target(s) in 0.40s
|
上述命令以release模式生成了内核可执行文件,它的位置在 target/riscv64gc-unknown-none-elf/release/os。
手动加载内核可执行文件#
上面得到的内核可执行文件完全符合了我们对于内存布局的要求,但是不能将其直接提交给Qemu使用,因为它除了实际会用到的代码和数据段之外,还会有一些多余的元数据,这些元数据无法被Qemu在加载文件时利用,且会使代码和数据段被加载到错误的位置。如下图所示:
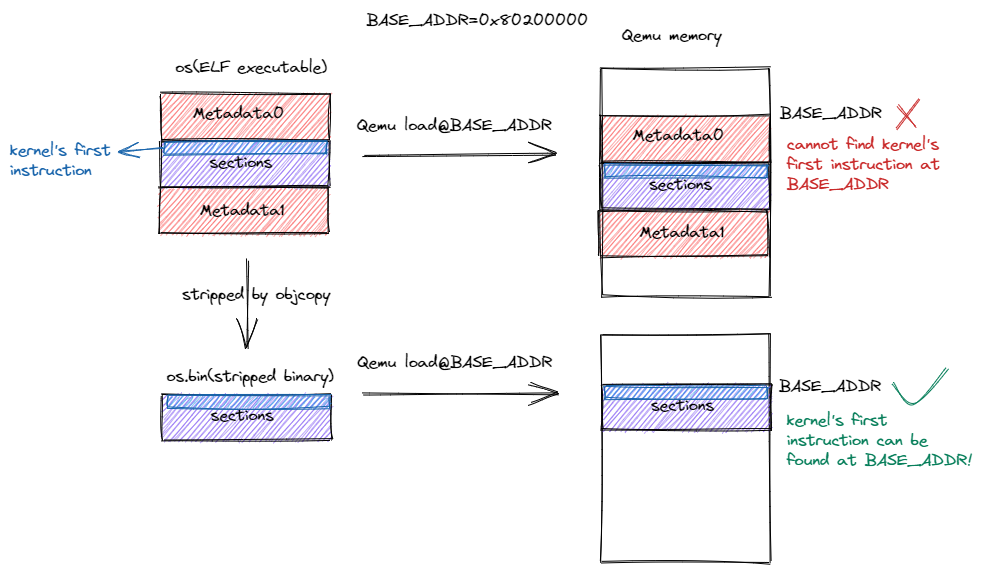
如果直接将内核可执行文件os加载到Qemu内存的0x80200000处,由于内核可执行文件的开头是一段缘数据,这会导致Qemu内存在0x80200000无法找到内核第一条指令,也就意味着RustSBI无法正常将计算机控制权转交给内核。
执行命令可丢弃内核可执行文件中的元数据得到内核镜像:
1
| $ rust-objcopy --strip-all target/riscv64gc-unknown-none-elf/debug/os -O binary target/riscv64gc-unknown-none-elf/os.bin
|
基于GDB验证启动流程#
1
2
3
4
5
6
| $ qemu-system-riscv64 \
-machine virt \
-nographic \
-bios ../bootloader/rustsbi.bin \
-device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000 \
-s -S
|
上述命令在之前提到的启动Qemu模拟器的命令的基础上加了-s、-S两个参数:
-s:使Qemu监听本地TCP端口1234等待GDB客户端连接-S:使Qemu在收到GDB的请求后再开始运行
启动GDB客户端连接到Qemu:
1
2
3
4
| $ riscv64-unknown-elf-gdb \
-ex 'file target/riscv64gc-unknown-none-elf/release/os' \
-ex 'set arch riscv:rv64' \
-ex 'target remote localhost:1234'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| (gdb) b *0x80200000 # 在0x80200000处打个断点
Breakpoint 1 at 0x80200000
(gdb) c
Continuing.
Breakpoint 1, 0x0000000080200000 in ?? ()
(gdb) x/5i $pc
=> 0x80200000: li ra,100 # 可以看到我们entry.asm中的 li x1, 100,ra是寄存器x1的别名
0x80200004: unimp
0x80200006: unimp
0x80200008: unimp
0x8020000a: unimp
(gdb) si # 继续执行下一条指令
0x0000000080200004 in ?? ()
(gdb) p/d $x1 # 以十进制打印寄存器x1的值
$1 = 100
(gdb) p/x $sp # 检查此时栈指针sp的值
$2 = 0x0
|
为内核支持函数调用#
经过上述流程,我们已经成功的在Qemu上执行了内核的第一条指令,它是我们在entry.asm中手写的汇编代码得到的。但是我们的目的并不是使用汇编来编写内核,绝大部分功能还是要是用Rust来实现。
不过为了将控制权转交给我们使用Rust编写的内核入口,我们还是需要编写部分汇编代码。和之前一样,这些汇编代码还是放在entry.asm中并在控制权被转交给内核后最先被执行,但是它们的功能会较之前更加复杂:
- 首先设置栈,使得在内核中进行函数调用
- 之后直接调用使用Rust编写的内核入口点,从而控制权便被移交给了Rust代码
函数调用与栈#
首先从汇编指令的级别分析一段程序的执行,假设CPU一次执行的指令的物理地址序列为${a_n}$。
其中最简单的就是CPU一条一条连续向下执行指令,但执行序列并不总是符合这种模式,当位于物理地址${a_n}$的指令是一条跳转指令时,该模式可能被破坏。跳转指令对应于我们在程序中构造的控制流(Control Flow)的多种不同结构,比如分支结构和循环结构,用来实现这两种结构的跳转指令,只需实现跳转功能,也就是将pc寄存器设置到一个指定地址即可。
另一种控制流结构则显得更加复杂:函数调用(Function Call)。同样使用汇编指令来分析函数调用的过程,在调用函数时,需要有一条指令跳转到被调用函数的位置,但是在被调用函数返回时,我们需要返回到那条掉转过来的指令的下一条继续执行。如果是之前提到的两种结构,执行结束后返回的地址在编译期已确定,但是对于函数调用来说,在对应的函数调用发生之前是不知道的,也就是说函数调用的返回跳转是跳转到一个函数调用发生时才能确定的地址。
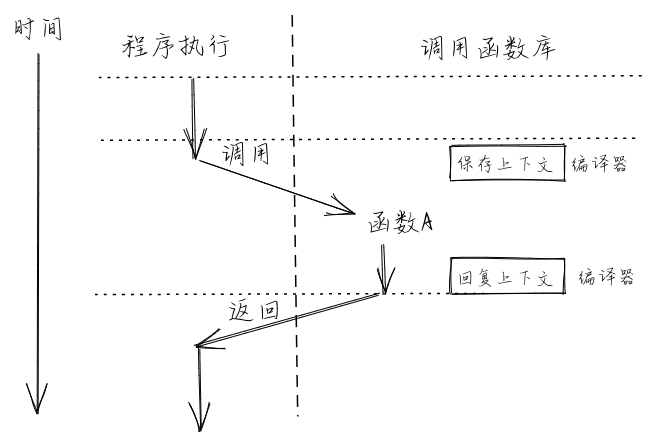
对此,指令集必须给用于函数调用的跳转指令一些额外的能力,而不只是单纯的跳转。在RISC-V架构上,有两条指令即符合这样的特征:
| 指令 | 指令功能 |
|---|
| jal rd, imm[20:1] | rd<-pc+4pc<-pc+imm |
| jalr rd, (imm[11:0])rs | rd<-pc+4pc<-rs+imm |
rs:表示源寄存器(Source Register)imm:表示立即数(Immediate),是一个常数,与源寄存器构成了输入部分rd:表示目标寄存器(Destination Register),它是指令的输出部分
从中可以看出,这两条指令在设置pc寄存器完成跳转指令之前,将当前跳转指令的下一条指令地址保存在了rd寄存器中。在RISC-V架构中,通常使用ra寄存器作为rd对应的具体寄存器,因此在函数返回的时候,直接跳转回ra保存的地址即可。
在进行函数调用时,通过jalr指令保存返回地址并实现跳转;在函数调用结束返回时,通过ret伪指令回到跳转之前的下一条指令继续执行。这样,RISC-V的两条指令就实现了函数调用流程的核心机制。
由于我们在ra寄存器中保存返回地址,要保证在函数执行的全程不发生变化,否则ret之后就会跳转到错误的位置。事实上编译器除了函数调用的相关指令外确实是基本不使用ra寄存器,也就是说在函数中没有调用其他函数,那ra的值不会发生变化。但是在实际编写代码的过程中,我们常常有函数多层嵌套调用的场景,如果我们试图在函数F中调用函数G,那么在跳转到函数G的同时,ra会被覆盖成这条指令的下一条地址,而ra之前所保存的函数F的返回地址将永久丢失。
因此,为了能够正确实现嵌套函数调用的控制流,我们必须通过某种方式来保证在一个函数调用子函数的前后,ra寄存器的值不发生变化。但实际上,这并不仅仅局限于ra一个寄存器,而是作用于所有的通用寄存器。由于编译器是独立编译每个函数的, 因此一个函数并不知道它所调用的子函数修改了哪些寄存器。而对于一个函数而言,在调用子函数的过程中某些寄存器的值被覆盖的确会对这个函数的执行产生影响。
我们将由于函数调用,在控制流转移前后需要保持不变的寄存器集合称之为函数调用上下文(Function Call Context)。
由于每个CPU只有一套寄存器,所以我们若想在调用子函数时保持函数上下文不变,就需要物理内存的辅助。确切的说,就是在子函数调用之前,我们需要在物理内存中的一个区域保存(Save)函数调用上下文中的寄存器;而在子函数执行完毕后,我们会从内存中上述同样的区域读取并恢复(Restore)函数调用上下文中的寄存器。实际上,这一工作由子函数的调用者和被调用者共同完成。函数调用上下文中的寄存器被分为如下两类:
被调用者保存(Callee-Saved)寄存器: 被调用的函数可能会覆盖这些寄存器,需要被调用者函数来保存的寄存器。即由被调用的函数来保证调用前后,这些寄存器保持不变。调用者保存(Caller-Saved)寄存器: 被调用的函数可能会覆盖这些寄存器,需要调用者函数来保存的寄存器。即由发起调用的函数来保证调用前后,这些寄存器保持不变。
具体过程如下:
- 调用函数: 首先保存不希望在函数调用过程中发生变化的
调用者保存寄存器,然后通过jal/jalr指令调用子函数,返回之后恢复这些寄存器。 - 被调用函数: 在被调用函数的起始,先保存函数执行过程中被用到的
被调用者保存寄存器,然后执行函数,在函数退出之前恢复这些寄存器。
调用规范#
调用规范(Calling Convention)约定在某个指令集架构上,某种编程语言的函数调用如何实现。它包括以下内容:
- 函数的输入参数和返回值参数如何传递
- 函数调用上下文中调用者/被调用者保存寄存器的划分
- 其它的在函数调用流程中对于寄存器的使用方法
RISC-V架构上的C语言调用规范
之前提到的函数调用时需要在物理内存中保存上下文中的寄存器,实际上,这块物理内存更加确切的名字是栈(Stack)。sp寄存器用来保存栈指针(Stack Pointer),它指向内存中的栈顶地址。在RISC-V架构中,栈从高地址向低地址增长。在一个函数中,作为起始的开场代码负责分配一块新的栈空间,即将sp的值减小相应的字节数,于是物理地址区间$[新sp, 旧sp)$对应的物理内存的一部分便可以被这个函数用来进行函数调用上下问的保存/恢复,这块物理地址被称为这个函数的栈帧(Stackframe)。同理,函数中的结尾代码负责将开场代码分配的栈帧回收,也就是将sp的值增加相同的字节数以回到分配之前的状态。这同样也解释了为何sp是一个被调用者保存的寄存器。
在合适的编译选项设置之下,一个函数的栈帧内容可能如下所示:
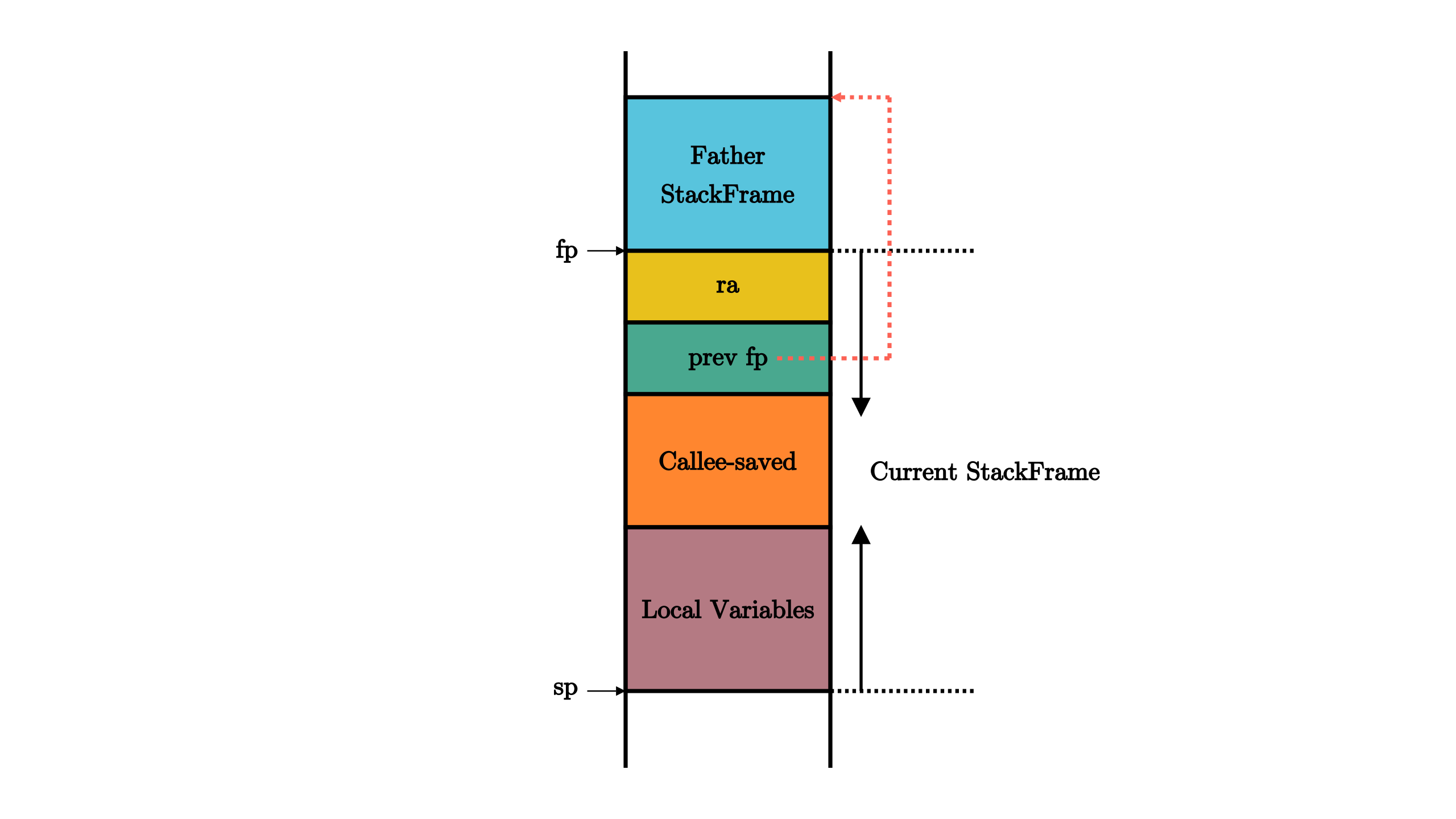
它的开头和结尾分别在sp(x2)和fp(s0)所指向的地址。按照地址从高到低分别由以下内容,它们都是通过sp加上一个偏移量来访问的:
ra寄存器保存其返回之后的跳转地址,调用者保存寄存器- 父亲栈帧的结束地址
fp,被调用者保存寄存器 - 其他被调用者保存寄存器
s1~s11 - 函数所使用到的局部变量
因此,栈上多个fp信息实际上保存了一条完整的函数调用链,通过适当的方式我们可以实现对函数调用关系的跟踪。
至此,此节基本说明了函数调用如何实现。不过我们暂时可以忽略这些细节,我们只需在初始化阶段完成栈道设置,也就是设置好栈指针sp寄存器,编译器会帮助我们自动完成后面的函数调用相关机制的代码生成。
分配并使用启动栈#
1
2
3
4
5
6
7
8
9
10
11
12
13
| # os/src/entry.asm
.section .text.entry
.global _start
_start:
la sp, boot_stack_top # 将指针sp设置为之前分配的启动栈栈顶地址
call rust_main # 调用Rust编写的内核入口点rust_main,将控制权交给Rust代码
.section .bss.stack # 将这块空间放置在一个名为.bss.stack的段中
.global boot_stack
boot_stack:
.space 4096*16 # 预留4096*16字节64KiB的空间用作程序的栈空间
.global boot_stack_top
boot_stack_top:
|
1
2
3
4
5
6
7
| # os/src/linker.ld
.bss : {
*(.bss.stack) # .bss.stack段被汇集到.bss段中
sbss = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
| // os/src/main.rs
#![no_std]
#![no_main]
mod lang_items;
use core::arch::global_asm;
global_asm!(include_str!("entry.asm"));
#[no_mangle]
pub fn rust_main() -> ! {
loop {}
}
|
在main.rs中,通过宏对rust_main标记,避免编译器对它的名字进行混淆,否则在链接的时候,entry.asm将找不到main.rs提供的外部符号rust_main,导致链接失败。在rust_main的开场白中,我们将第一次在栈上分配栈帧并保存函数调用上下文,它是内核运行全程最深的栈帧。
我们顺便完成对.bss段的清零,这是内核初始化很重要的一部分,在使用任何被分配到.bss段的全局变量之前我们需要确保.bss段已被清零。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // os/src/main.rs
#![no_std]
#![no_main]
mod lang_items;
use core::arch::global_asm;
global_asm!(include_str!("entry.asm"));
#[no_mangle]
pub fn rust_main() -> ! {
clear_bss();
loop {}
}
fn clear_bss() {
extern "C" {
fn sbss();
fn ebss();
}
(sbss as usize..ebss as usize).for_each(|p| unsafe { (p as *mut u8).write_volatile(0) })
}
|
链接脚本linker.ld给出了全局符号sbss和ebss,并指出了需要被清零的.bss段的起始和终止地址。所以只需遍历该地址区间并逐字节清零即可。
基于SBI服务完成输出和关机#
使用RustSBI提供的服务#
RustSBI介于底层硬件和内核之间,是内核的底层执行环境。RustSBI提供的执行环境除了为上层应用进行环境初始化,并将计算机控制权移交给内核,还有另一项职责:在上层应用运行时提供服务。当内核发出请求时,计算机转由RustSBI控制来响应内核的请求,待请求处理完毕后,计算机控制权会被交还给内核。但是由于内核并没有与RustSBI链接,内核无法通过函数调用请求RustSBI提供的服务,我们仅仅使用RustSBI构建后的可执行文件,因此内核对于RustSBI的符号一无所知。实际上,内核需要通过另一种复杂的方式来“调用”RustSBI服务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // os/src/sbi
use core::arch::asm;
#[inline(always)]
fn sbi_call(which: usize, arg0: usize, arg1: usize, arg2: usize) -> usize {
let mut ret;
unsafe {
asm! {
"ecall",
inlateout("x10") arg0=>ret,
in("x11") arg1,
in("x12") arg2,
in("x17") which,
}
}
ret
}
|
我们将内核与RustSBI通信的相关功能在子模块sbi中实现,因此需要在main.rs中加入mod sbi将该子模块加入项目中。
在os/src/sbi.rs中:which表示请求RustSBI的服务类型,arg0~arg2表示传递给RustSBI的三个参数,而RustSBI在将请求处理完毕后,会给内核一个返回值,这个返回值也被sbi_all返回。
我们可以在sbi.rs中定义RustSBI支持的服务类型常量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| // os/src/sbi.rs
#![allow(unused)]
const SBI_SET_TIMER: usize = 0;
const SBI_CONSOLE_PUTCHAR: usize = 1;
const SBI_CONSOLE_GETCHAR: usize = 2;
const SBI_CLEAR_IPI: usize = 3;
const SBI_SEND_IPI: usize = 4;
const SBI_REMOTE_FENCE_I: usize = 5;
const SBI_REMOTE_SFENCE_VMA: usize = 6;
const SBI_REMOTE_SFENCE_VMA_ASID: usize = 7;
const SBI_SHUTDOWN: usize = 8;
use core::arch::asm;
#[inline(always)]
fn sbi_call(which: usize, arg0: usize, arg1: usize, arg2: usize) -> usize {
let mut ret;
unsafe {
asm! {
"ecall",
inlateout("x10") arg0 => ret,
in("x11") arg1,
in("x12") arg2,
in("x17") which,
}
}
ret
}
|
服务SBI_CONSOLE_PUTCHAR可以用来在屏幕上输出一个字符,我们可以将这个功能使用sbi_call函数来封装:
1
2
3
| pub fn console_putchar(c: usize) {
sbi_call(SBI_CONSOLE_PUTCHAR, c, 0, 0);
}
|
SBI_SHUTDONW提供关机服务,同样可以封装:
1
2
3
4
| pub fn shutdown() -> ! {
sbi_call(SBI_SHUTDOWN, 0, 0, 0);
panic!("It should shutdown!")
}
|
实现格式化输出#
上面实现的console_putchar功能过于受限,如果想打印一行Hello,world!则需要多次调用。接下来我们尝试编写基于console_putchar的println!宏。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| // os/src/console.rs
#![allow(unused)]
use crate::sbi::console_putchar;
use core::fmt::{self, Result, Write};
struct Stdout;
impl Write for Stdout {
fn write_str(&mut self, s: &str) -> Result {
for c in s.chars() {
console_putchar(c as usize);
}
Ok(())
}
}
pub fn print(args: fmt::Arguments) {
Stdout.write_fmt(args).unwrap();
}
#[macro_export]
macro_rules! print {
($fmt: literal $(, $($arg: tt)+)?) => {
$crate::console::print(format_args!($fmt $(, $($arg)+)?));
}
}
#[macro_export]
macro_rules! println {
($fmt: literal $(, $($arg: tt)+)?) => {
$crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?));
}
}
|
处理致命错误#
错误处理是编程中重要的一环,它能够保证程序的可靠性和可用性。Rust将错误分为可恢复和不可恢复错误两大类,这里我们主要关心不可恢复错误,在遇到不可恢复错误时,Rust程序会直接报错退出,使用panic!宏便会直接出发一个不可恢复错误并使得程序退出。在我们的内核中,目前不可恢复错误的处理机制还不完善:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| // os/src/lang_items.rss
use crate::println;
use crate::sbi::shutdown;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
if let Some(location) = info.location() {
println!(
"Panicked at {}:{} {}",
location.file(),
location.line(),
info.message().unwrap()
);
} else {
println!("Panicked: {}", info.message().unwrap());
}
shutdown()
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| // os/src/main.rs
#![no_std]
#![no_main]
#![feature(panic_info_message)]
mod lang_items;
mod sbi;
#[macro_use]
mod console;
use core::arch::global_asm;
global_asm!(include_str!("entry.asm"));
#[no_mangle]
pub fn rust_main() -> ! {
clear_bss();
println!("Hello, world");
panic!("Shutdown machine!");
}
fn clear_bss() {
extern "C" {
fn sbss();
fn ebss();
}
(sbss as usize..ebss as usize).for_each(|p| unsafe { (p as *mut u8).write_volatile(0) });
}
|
注意:在main.rs中我们需要加入#![feature(panic_info_message)]才能通过PanicInfo::message获取报错信息。
使用Qemu运行内核,可以得到结果:
1
2
| Hello, world
Panicked at src/main.rs:18 Shutdown machine!
|
实践作业-实现彩色化LOG#
详细原理:ANSI转义序列
1
| echo -e "\x1b[31mhello world\x1b[0m"
|
1
2
3
4
5
6
7
8
9
| # Cargo.toml
[package]
name = "os"
version = "0.1.0"
edition = "2021"
[dependencies]
log = "0.4"
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| // os/src/logger.rs
use log::{self, Level, LevelFilter, Log};
use crate::println;
struct Logger;
impl Log for Logger {
fn enabled(&self, _metadata: &log::Metadata) -> bool {
true
}
fn log(&self, record: &log::Record) {
if !self.enabled(record.metadata()) {
return;
}
let color = match record.level() {
Level::Error => 31,
Level::Debug => 32,
Level::Info => 34,
Level::Trace => 90,
Level::Warn => 93,
};
println!(
"\u{1B}[{}m[{:>5}] {}\u{1B}[0m",
color,
record.level(),
record.args(),
);
}
fn flush(&self) {}
}
pub fn init() {
static LOGGER: Logger = Logger;
log::set_logger(&LOGGER).unwrap();
log::set_max_level(match option_env!("LOG") {
Some("ERROR") => LevelFilter::Error,
Some("WARN") => LevelFilter::Warn,
Some("INFO") => LevelFilter::Info,
Some("DEBUG") => LevelFilter::Debug,
Some("TRACE") => LevelFilter::Trace,
_ => LevelFilter::Trace,
});
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| // os/src/main.rs
#![no_main]
#![no_std]
#![feature(panic_info_message)]
mod lang_items;
mod sbi;
mod logger;
use log::*;
#[macro_use]
mod console;
core::arch::global_asm!(include_str!("entry.asm"));
#[no_mangle]
pub fn rust_main() -> ! {
extern "C" {
fn stext();
fn etext();
fn srodata();
fn erodata();
fn sdata();
fn edata();
fn sbss();
fn ebss();
fn boot_stack();
fn boot_stack_top();
}
clear_bss();
logger::init();
error!("Hello, rCore!");
info!(".text [{:#x}, {:#x}]", stext as usize, etext as usize);
debug!(".rodata [{:#x}, {:#x}]", srodata as usize, erodata as usize);
trace!(".data [{:#x}, {:#x}]", sdata as usize, edata as usize);
warn!(".bss [{:#x}, {:#x}]", sbss as usize, ebss as usize);
error!(
".stack [{:#x}, {:#x}]",
boot_stack as usize, boot_stack_top as usize
);
panic!("Shutdown machine!");
}
fn clear_bss() {
extern "C" {
fn sbss();
fn ebss();
}
(sbss as usize..ebss as usize).for_each(|p| unsafe { (p as *mut u8).write_volatile(0) });
}
|
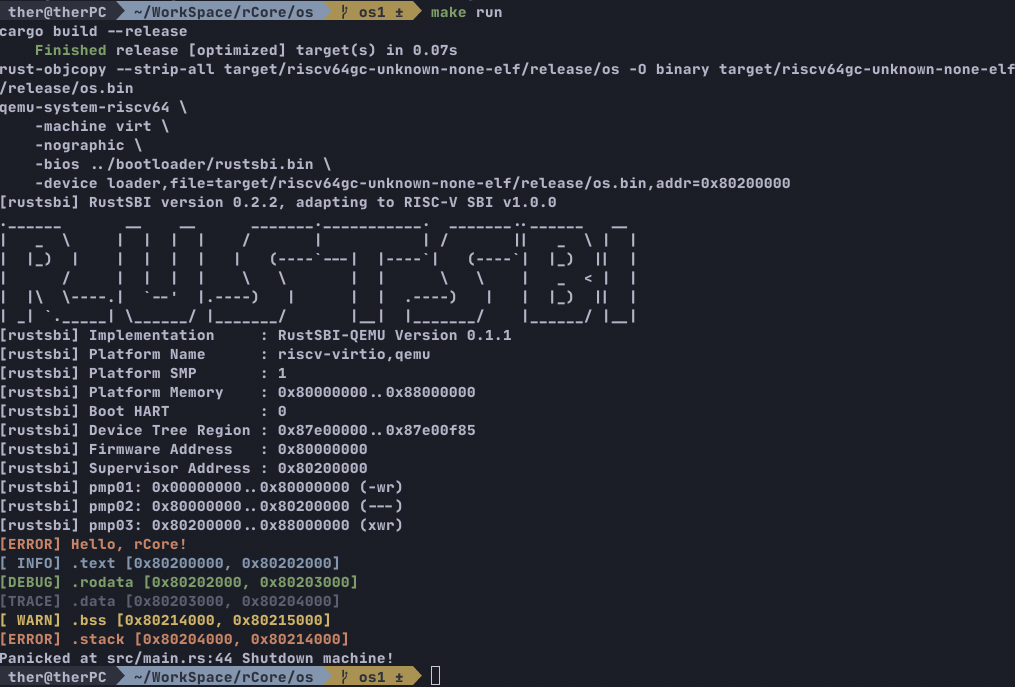
运行结果如下: